Data Science project end-to-end: use-case in banking and collection
That is a summary of Crayon’s project delivered for the international holding operating in the debt collection domain.
Table of contents
Intro
Part I - Business overview
Counterparties
Debt lifecycle
Challenges of Collection Agencies
Part II - Data Science applications
Use-cases for Data Science
ML tasks
Data structure
Classification task
Dataset split
Feature engineering
Feature correlations
Part III - Recap
Insights
Infrastructure
Takeaways
Wrapping upIntro
When you hear about AI in banking & finance, you probably think of automated stock trading or credit scoring. Debt collection (DC), on the other side, is a bit in the shadow, although it’s quite an important part of the whole financial cycle. The potential of data science there has not been explored thoroughly. Hence, there is huge room for establishing the best practices.
In this post, I will guide you through the main stages of a debt collection project from the perspective of data. Starting from an initiation phase where the business struggles with a particular problem. Up to an implementation phase where a cross-functional team can deliver direct value to the company. In addition, we will touch on some important challenges, like data quality and security, validation of results, and collaboration among different teams.
Counterparties
First, let’s introduce the main actors in this area. It all starts with the organization that issues a loan. That could be a bank with a mortgage, a telecom company with a phone contract, or a microcredit lender with a microloan.

Together with a customer (or a debtor), they arrange a payment plan, according to which the loan is repaid with monthly installments. Most often everything goes according to this plan, but that’s not the topic of our post today.
On some bad occasions, the customer is not able to transfer an installment, and that is called an overdue. If a couple of overdues happen in a row, the bank starts some in-house collection procedures. But this is not the core business of most banks, telecom companies, or microcredit boutiques. That’s why it’s easier to just sell these non-paying debts to a 3rd party, a collection agency (CA).
Debt lifecycle
To make it a bit clearer let’s have a look at a typical lifecycle of a debt. Here are the main stages:
1. Regular payments in a bank
2. Past due events
3. Acquisition by a CA
4. Setting a payment plan
5. Scheduled interactions
6. Total repayment or legal stageThese steps are obvious, but just a couple of remarks. Steps 4 and 5 require direct interaction between the debtor and an agency. Sometimes it’s not that easy to reach a customer, so payment plans are set automatically then.
Eventually, there are 2 paths for a debtor: amicable repayment or legal process. The former is a usual way in case the debtor is following the plan. Otherwise, the latter comes into place, and here the court is involved.
Challenges of CAs
The first stage of this project was to define the main challenges from a business side, to evaluate the best opportunities where a data-driven approach would be most efficient.
We grouped these challenges into 3 pillars:

A. Payment plan
It might sound weird, but the initial challenge is to reach a debtor. Many people are not disclosing their contacts and don’t want to be reached. Agents could spend quite some time trying to get the debtor’s phone number or home address.
Another big thing is discounts. There are smart people in the DC domain, and they understand that since the customer hadn’t paid the bank before, he/she might have some issues with money. In that case, it makes sense to ask them to repay not the full sum of the loan debt, but the diminished one with a discount. The question is “how much of a discount”? A small one won’t lead to any progress with the customer, but a large one will lead to negative profits. There’s some optimum, that shifts this task to a mathematical domain.
All the actions performed by CA cost money. Agents have to write letters, call debtors, update Excel spreadsheets, and so on. All of it represents amicable costs.
B. Legal aspects
Our partner operates in multiple different countries with various legal procedures. In some countries there exists a so-called “contact-free” period, when the CA is not allowed to contact a debtor. Usually, it lasts for 1 month, meaning that all strategic decisions must be taken without direct interaction with newly acquired debtors.
Some countries allow a bankruptcy procedure for private individuals. One can apply for it to state authorities, and if granted, their debts will be written off. That outcome is very negative for CAs, so it makes sense to be proactive in this area. Probably offering discounts more actively in advance.
If CA eventually decides to start a legal procedure, court costs should be considered, as they might be quite high relative to possible collection sums.
C. Technical issues
Collection agencies might have hundreds of thousands or millions of debtors. To run the business effectively there should be tailored strategies that are applicable to groups of debtors. Instead of handling debtors individually these strategies allow for some unification and generalization.
Data quality is an important aspect in most of the projects recently. We have to define what and how to collect, be able to prepare the data for analytics, and run the whole process consistently and effectively. We have to invest enough effort to ensure proper data quality, especially if data processing involves a lot of human intervention.
Handling interactions with the customers, supporting manual data preprocessing, and non-automated collection strategies involve a lot of manual labor. From the business perspective, that could be improved, which will allow CA’s employees to invest their effort into other valuable activities.
Use cases for Data Science
When looking through the aforementioned business challenges, we pointed out some tasks, that could be converted into analytical or machine learning problems in a clear way.
1. Grouping debtors by behavior
This task is very close to the usual credit scoring, which is done in almost any bank. CA must be aware of its customers’ intentions. The most reasonable aspect is how likely are customers willing to follow the payment plan. As a result of this task, strategists will have customers explicitly split into groups by their expected behavior. For example, customers with the [low, medium, high] intention to follow the payment plan.
2. Cashflow forecasting
The finance department of every company is highly interested to have forecasts of future revenues and expenses. That puts a cashflow forecasting task a high priority. In DC business revenue is the amount of money collected from the debtors, and expenses are all amicable, legal, and operational costs altogether. From a technical point of view, this task is usually solved via a time series and/or regression approach.
3. Better interactions
There are much more debtors than employees in a CA. Every agent must call hundreds of debtors on a weekly basis. It might also be the case that there is not enough manpower to call all debtors with a low intention to follow the payment plan. In this case, we must do 2 things:
- prioritize the customers
- optimize the time-to-call for collection agents
There is specific software that tends to decrease the waiting time for debt agents when they are calling the debtors. There is always room for improvement when it goes to optimization tasks in machine learning.
4. Optimization of discounts
Discounts are a topic of great interest in DC business. They can be a great incentive for the debtors to keep following the payment plan. Obviously, we need to find the appropriate amount to cut, not too high, not too low. That is quite a typical task in marketing where you’re optimizing for a promotion value in order to maximize the revenue.
5. Bankruptcy prevention
The ability to predict the applications for restructuring or bankruptcy is essential. If the debtor starts this procedure, it will take a lot of time, and might end in a total loss of debt for a CA. This is an analog of a churn prediction for b2c services. From a technical point of view, we run a classification model that outputs the probability of filing a restructuring application.
ML tasks
Out of all these data science tasks we picked 3 most relevant and straight-forward ones and formulated exact machine learning problems:
- Predict the propensity to pay
- Predict the debt restructuring
- Estimate payment amounts
The first two are classification models. They predict whether some event will happen or not. More specifically, a classification model outputs the probability of an event happening.
The last model is a regression one. We predict the exact value of a future payment.
In all models, we have to specify the horizon: the time interval in the future for which we are making predictions. It could be 1 month, 3 months, a quarter, or a year.
These 3 models have the following outputs, or predictions:
- The probability that payment will take place in the following N months
- The probability that a debtor will apply for a restructuring in the following N months
- The payment sum we expect a debtor to pay in the following N months
Data Structure
It’s time to look at the data structure to understand what exactly is available for modeling.
There are 3 types of data entities:

1. Debt and debtor information
The usual features of a debt are debt amount (initial and current), product type, number of days past due, etc. When it comes to debtor features, we must be careful, as most of them are sensitive and should be used according to local legislation. It might be illegal or unfair to add age, gender, income amount to the model.
Most of the features are static here. Only a couple change in time (like current debt amount).
2. Interaction data
Here we have the events that happen between a CA and customers: phone calls, e-mails, letters. These events have features, like the topic of a call, its result, and some others. Also, we can calculate different statistics, like average amount of outgoing calls in the last 6 months.
3. Target actions
These are the events we want to predict: application for restructuring or payment. For the latter, we could be interested in its amount and in historical payments, which form a behavior of a customer.
Classification task
In this article, we will focus a bit more on classification tasks, because I like them more 😊 and they are easier to handle and interpret.
1. Metrics
Before starting any modeling, we must agree on the metrics we optimize and track, as well as the ones we probably don’t care too much about. My usual approach with classification tasks is to deal with “generic” metrics at first, and only then jump to the ones depending on a threshold.
My go-to metric is AUC (area under the curve). After obtaining a sufficient AUC I’m sure the task is generally learnable. That means we could already think of what is preferable in a well-known “precision-recall” tradeoff. A possible way here is to go to stakeholders and ask them what error type (I or II) costs more for business. After that, we could optimize for higher recall or precision. Or sometimes F1-score if both are of the same importance to us.
2. Models
In this project we utilized only well-established models:
- Logistic regression (as a baseline)
- Random Forest (as a main model during the whole project)
- Gradient Boosting (for further exploration and optimization)
We decided not to go into deep learning, as it probably won’t be significantly better with the current size of datasets.
Dataset split
For experiments, we always used cross-validation to feel more confident with the results and to find the best parameters. But there are also 2 very important things that I would like to elaborate on.
1. Representative data
We have historical data for the last couple of years for most of the debtors. In many machine learning problems, one tries to get the most recent data to train the model on. But the financial domain is very sensitive to worldwide sudden changes like COVID in 2020. For the sake of more generalizing models, it might happen to include data samples from different historical periods in the final training dataset.
2. Metric over-estimation
For every debtor in a portfolio, we have multiple data points (corresponding to different dates). Very often it happens that the features of a particular debtor do not change drastically from month to month. You can see that on the left part of the figure:

Features [initial debt, paid 1M] remain the same in both Oct-2021 and Nov-2021. Feature debt current has changed slightly. Splitting the dataset into train and test in that way will lead to higher metrics because the model will need to guess less. There will be similar rows both in train and test splits.
To avoid this, we used the approach on the right. We get the data from a particular debtor only once: either in train or in test.
Metrics are lower in this case, but it is fairer. Expectation management is particularly important in data science projects.
Feature engineering
Not all the data is ready to be used in modeling right away. Also, we might think of more features to construct, to help our models gain better results. Here are some examples.
1. Non-linearity
Models based on trees are of course non-linear, but it will be useful if we explicitly add some non-linear interactions between features:

2. Processing customer calls and emails
There are a lot of various outcomes of the calls. It might be “didn’t reach the customer”, “customer promised to pay in 2 months” or “customer said it’s not the right time to talk”.
After some analysis we decided to split all these interactions into a couple of groups, based on the outcome:
1. positive outcome
2. neutral outcome
3. negative outcome
4. NA/unknown3. Events aggregation
In the raw data, one row represents one event, but for modeling, we needed something more compact:

“Group by” transformed our data into different statistics. For any given debt we can now have a number of payments for the last 3 months or an average payment overall.
Feature correlations
After the steps described before, we got a lot of correlated features:

This leads us to the next project stages: exploring feature importances, ensuring consistency of model outputs. These topics are not in the scope of a current article, so I will emphasize one thing only.
None of the features is highly correlated with the target (the last row of the matrix, marked with an orange arrow). We have to be patient and try multiple approaches in order to build a neat model.
Insights
I think it doesn’t make sense to list here the final metrics, model parameters, or sets of features. They are very specific from project to project and won’t give you a hint of it. But here are some insights that seem interesting to me and are worth sharing.
1. Propensity to pay
Above we talked about the dataset split and over-under-estimating the metric. Here I would like to show how it looks in practice. In the example of a “Propensity to pay” model. It predicts the probability that a debtor will make a payment in the next N months.
Every debt has its age. During the 1st month after the acquisition (the moment when a CA acquired a debt), it is 1, and then it keeps growing. For example, a year after the acquisition it’s 12.
To explore the data in detail, we split it into different parts based on the debt age. Afterward, we apply a usual “train-test” approach for every single step independently. In the end, we have model metrics for different ages of debts:

There are some nice observations on this graph.
It is easier to predict for a shorter time horizon
The shorter our time horizon for predictions is — the better the metrics are. The red line (prediction for the next 1 month) is almost always higher than 2 others (predictions for 3 and 6 months ahead respectively). That goes along with common sense, as it’s easier to produce short-term forecasts rather than long-term.
The metric changes drastically in time
Just after the acquisition we don’t know much about the debt and the debtor, hence our model quality is quite low (~0.67 AUC). After 2 months we have already obtained some meaningful information about debtor behavior, and the metric increases up to 0.8–0.83 for the upcoming months. After a debt spends a year in our portfolio, we are almost sure about its future. The model demonstrates the AUC around 0.95. It is a very good result, but not valuable from a business perspective. If the customer is not paying for a year, most of the collection agencies will tend to send him/her to the legal stage.
That’s why we should focus on model metrics for the first months after the acquisition.
2. Payment prediction
This model is a regression one, where we predict the payment sum for the debt in the following N months.
I didn’t focus a lot on this model before, because its results are quite disappointing:

There are some outliers in the data: we see them as single dots on the left part of the graph. The model couldn’t fit that very well — some of the most widely used metrics demonstrate a very low prediction power. MAE is almost as high as the mean target, R squared is only 17% and MAPE is 66%. Basically, I would not recommend using this model in production for payment value prediction.
But there is another observation — the means of true and predicted targets are quite close. The model did quite a good job of averaging the predictions. Given this result, we could use these means for forecasting the total cash flow.
Mean prediction * number of debts = total collection
We ran this approach for some consecutive months and got this graph:

As a result, we have a tool for predicting the cashflow for upcoming months — a very nice “side” result from a payment prediction model.
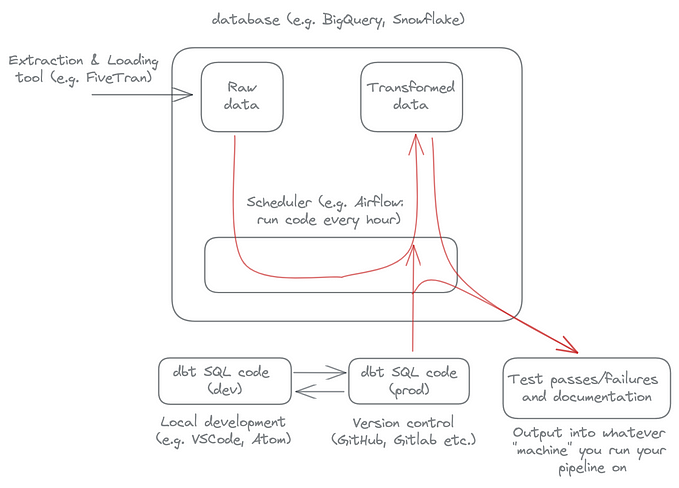
Infrastructure
Let’s finally briefly look at this project from an infrastructural point of view. It is implemented in Azure and consists of a couple of steps.
- Data ingestion
- Data preprocessing
- Model training
- Inference
This figure (special thanks to Sebastian Knigge for this amazing Solution Architecture) illustrates it more in-depth:

Azure Data Factory (ADF) is an orchestration tool that ingests the data from on-premises, does some preprocessing, and stores the results in Azure Storage Account.
Azure Machine Learning (AML) is a workspace where model training and model inference pipelines are sitting. AML retrieves the data from a storage account and runs one of the pipelines. Trained models are registered in a Model Registry, which is also a part of AML.
After the inference, the scored results are sent back: first to a storage account (to keep track of the history) and then to on-premises via ADF.
Takeaways
In this article, I tried to touch on multiple various aspects of a data-driven project for a Collection Agency. I would like to summarize them in these key takeaways.
1. ML can help
With its help, we can automate manual labor by clustering debtors into behavioral groups, streamline essential processes like optimization of making phone calls, and get important insights like predicting a future restructuring.
2. Strategy is key
From the very first steps of the project, it’s necessary to align with the stakeholders. They have solid domain knowledge and could guide data scientists in the right direction after some EDA presentations. You should also find a common ground in how you’re going to validate project results. Will it be beating the current manual baseline or a full-scale AB test.
3. Data quality
It’s better to collect all the data we have access to, of course with reasonable restrictions. And it is obvious that historical data should not be over-written. Otherwise, it’s extremely hard to build a consistent modeling approach.
The data can also change over time, it is called drifting in data science. The underlying distributions might change (like age groups of customers) or the model can output values in a significantly different range than at the moment of training. All these drifts should be monitored and taken care of by revisiting the project.
Wrapping up
As an outro, I would like to share my vision of a successful setup and mindset of a team:

The most prominent artifact of many data science projects is models. They bring direct value to the business but are helpless without clean and prepared data. Ingestion and preprocessing pipelines are impossible without proper infrastructure. More broadly, all analyses won’t be of any use without a reasonable strategy.
Finally, it is much easier to develop relevant strategies, maintain stable infrastructure and build precise models in a setup of cross-functional teams, where people with diverse backgrounds, knowledge profiles, and characters work hand in hand and support each other.